Niche Clustering
Spot-based Niche Clustering
Spot-based spatial transcriptomics assays capture spatially-resolved gene expression profiles that are somewhat closer to single cell resolution. However, each spot still includes a few number of cells that are likely originated from few number of cell types, hence transcriptomics profile of each spot would likely include markers from multiple cell types. Here, RNA deconvolution can be incorporated to estimate the percentage/abundance of cell types for each spot. We use a scRNAseq dataset as a reference to computationally estimate the relative abundance of cell types across the spots.
VoltRon includes wrapper commands for using popular spot-level RNA deconvolution methods such as RCTD and return estimated abundances as additional feature sets within each layer. These estimated percentages of cell types for each spot could be incorporated to detect niches (i.e. small local microenvironments of cells) within the tissue. We can process cell type abundance assays and used them for clustering to detect these niches.
Import Visium Data
For this tutorial we will analyze spot-based transcriptomics assays from Mouse Brain generated by the Visium instrument.
You can find and download readouts of all four Visium sections here. The Mouse Brain Serial Section 1/2 datasets can be also downloaded from here (specifically, please filter for Species=Mouse, AnatomicalEntity=brain, Chemistry=v1 and PipelineVersion=v1.1.0).
We will now import each of four samples separately and merge them into one VoltRon object. There are four brain tissue sections in total given two serial anterior and serial posterior sections, hence we have two tissue blocks each having two layers.
# dependencies
if(!requireNamespace("rhdf5"))
BiocManager::install("rhdf5")
# import visium data
library(VoltRon)
Ant_Sec1 <- importVisium("Sagittal_Anterior/Section1/", sample_name = "Anterior1")
Ant_Sec2 <- importVisium("Sagittal_Anterior/Section2/", sample_name = "Anterior2")
Pos_Sec1 <- importVisium("Sagittal_Posterior/Section1/", sample_name = "Posterior1")
Pos_Sec2 <- importVisium("Sagittal_Posterior/Section2/", sample_name = "Posterior2")
# merge datasets
MBrain_Sec_list <- list(Ant_Sec1, Ant_Sec2, Pos_Sec1, Pos_Sec2)
MBrain_Sec <- merge(MBrain_Sec_list[[1]], MBrain_Sec_list[-1],
samples = c("Anterior", "Anterior", "Posterior", "Posterior"))
MBrain_SecVoltRon Object
Anterior:
Layers: Section1 Section2
Posterior:
Layers: Section1 Section2
Assays: Visium(Main)
Features: RNA(Main) VoltRon maps metadata features on the spatial images, multiple features can be provided for all assays/layers associated with the main assay (Visium).
vrSpatialFeaturePlot(MBrain_Sec, features = "Count", crop = TRUE, alpha = 1, ncol = 2)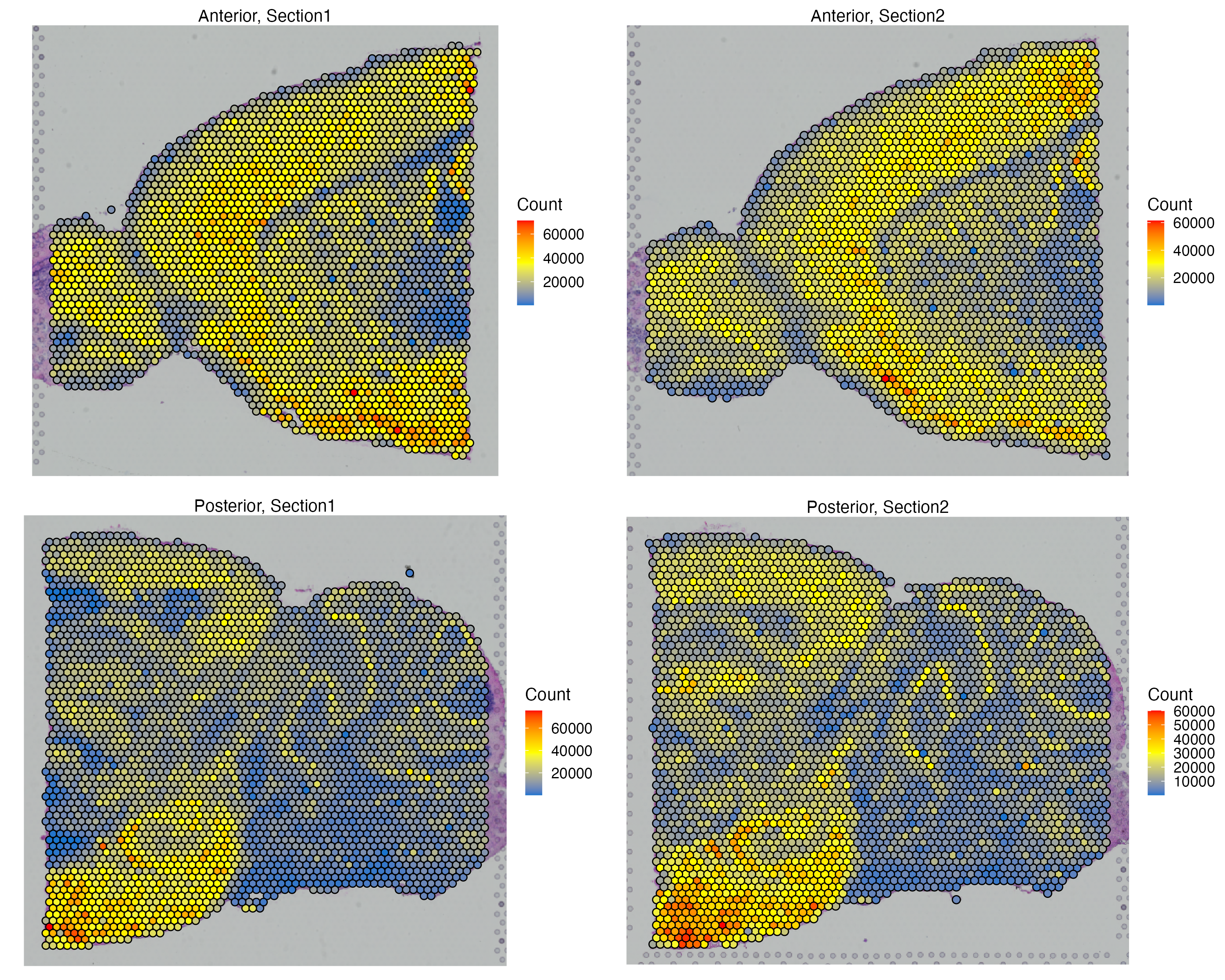
Import scRNA data
We will now import the scRNA data for reference which can be downloaded from here. Specifically, we will use a scRNA data of Mouse cortical adult brain with 14,000 cells, generated with the SMART-Seq2 protocol, from the Allen Institute. This scRNA data is also used by the Spatial Data Analysis tutorial in Seurat website.
# install packages if necessary
if(!requireNamespace("Seurat"))
install.packages("Seurat")
if(!requireNamespace("dplyr"))
install.packages("dplyr")
# import scRNA data
library(Seurat)
allen_reference <- readRDS("allen_cortex.rds")
# process and reduce dimensionality
library(dplyr)
allen_reference <- SCTransform(allen_reference, ncells = 3000, verbose = FALSE) %>%
RunPCA(verbose = FALSE) %>%
RunUMAP(dims = 1:30)Before deconvoluting Visium spots, we correct cell types labels and drop some cell types with extremely few number of cells (e.g. “CR”).
# update labels and subset
allen_reference$subclass <- gsub("L2/3 IT", "L23 IT", allen_reference$subclass)
allen_reference <- allen_reference[,colnames(allen_reference)[!allen_reference@meta.data$subclass %in% "CR"]]
# visualize
Idents(allen_reference) <- "subclass"
gsubclass <- DimPlot(allen_reference, reduction = "umap", label = T) + NoLegend()
Idents(allen_reference) <- "class"
gclass <- DimPlot(allen_reference, reduction = "umap", label = T) + NoLegend()
gsubclass | gclass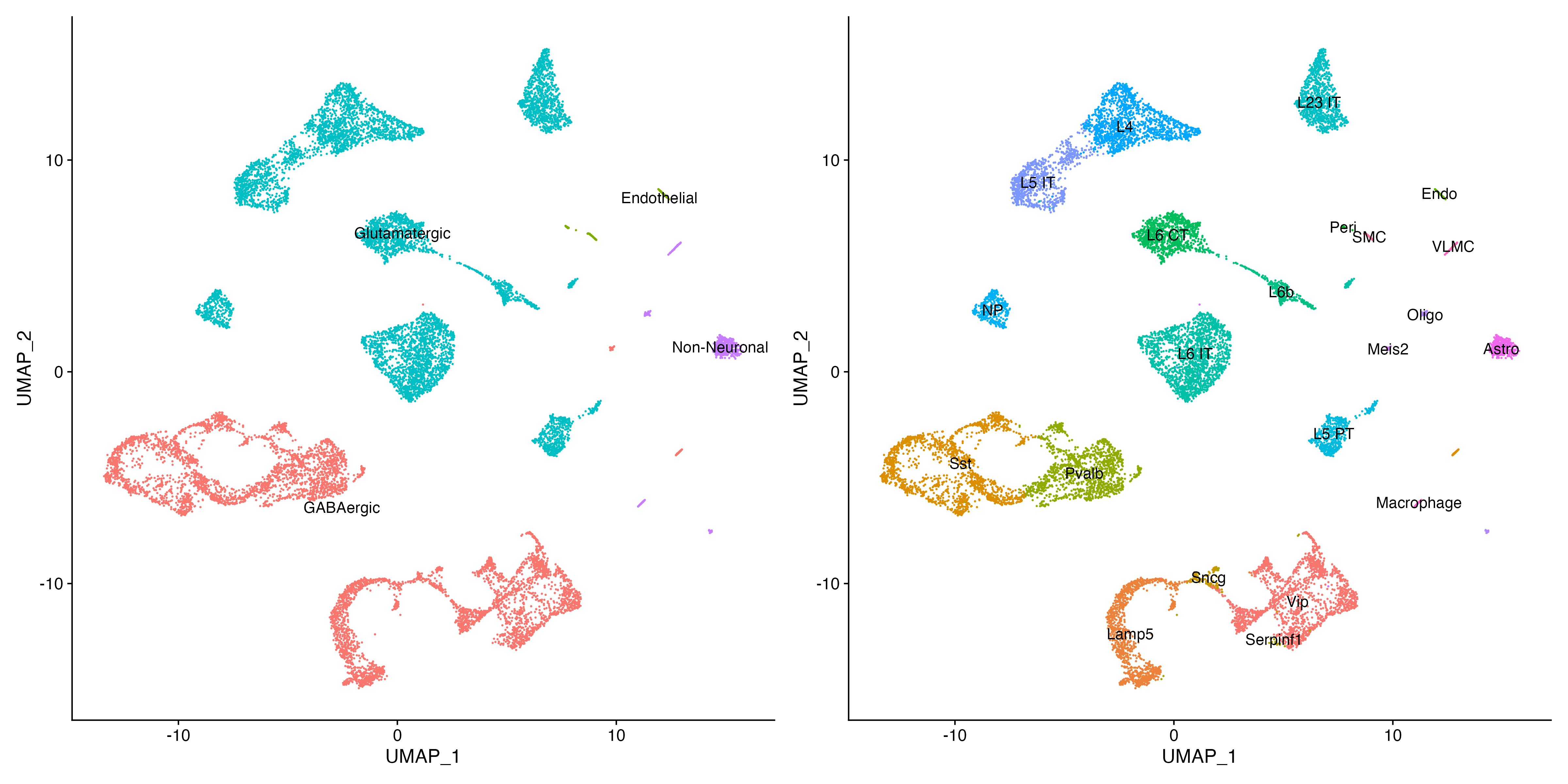
Spot Deconvolution with RCTD
In order to integrate the scRNA data and the spatial data sets within the VoltRon object and estimate relative cell type abundances for each Visium spot, we will use RCTD algorithm which is accessible with the spacexr package.
if(!requireNamespace("spacexr"))
BiocManager::install("spacexr")After running getDeconvolution, an additional feature set within the same Visium assay with name Decon will be created.
library(spacexr)
MBrain_Sec <- getDeconvolution(MBrain_Sec, sc.object = allen_reference, sc.cluster = "subclass", max_cores = 6)
MBrain_SecVoltRon Object
Anterior:
Layers: Section1 Section2
Posterior:
Layers: Section1 Section2
Assays: Visium(Main)
Features: RNA(Main) Decon We can now switch to the Decon feature type where features are cell types from the scRNA reference and the data values are cell types percentages in each spot.
vrMainFeatureType(MBrain_Sec) <- "Decon"
vrFeatures(MBrain_Sec) [1] "Astro" "Endo" "L23 IT" "L4" "L5 IT" "L5 PT"
[7] "L6 CT" "L6 IT" "L6b" "Lamp5" "Macrophage" "Meis2"
[13] "NP" "Oligo" "Peri" "Pvalb" "Serpinf1" "SMC"
[19] "Sncg" "Sst" "Vip" "VLMC" These features (i.e. cell type abundances) can be visualized like any other feature type.
vrSpatialFeaturePlot(MBrain_Sec, features = c("L4", "L5 PT", "Oligo", "Vip"),
crop = TRUE, ncol = 2, alpha = 1, keep.scale = "all")
Creating Niche Assay
Relative cell type abundances that are learned by RCTD and stored within VoltRon can now be used to cluster spots. These groups or clusters of spots can often be referred to as niches. Here, as a definition, a niche is a region or a collection of regions within tissue that have a distinct cell type composition as opposed to the remaining parts of the tissue.
To find niches, we first detect neighboring spots of each individual spot, and then aggregate the cell type abundances within these neighborhoods. For this, we first build a spatial neighborhood graph using getSpatialNeighbors function, since the assays of the VoltRon object are of spot type, a “radius” type method for building the spatial graph will capture immediate spot neighbors of each spot.
MBrain_Sec <- getSpatialNeighbors(MBrain_Sec, method = "radius")Then, we aggregate the counts of individual spots and neighbors.
vrMainFeatureType(MBrain_Sec) <- "Decon"
MBrain_Sec <- getNicheAssay(MBrain_Sec, graph.type = "radius")Clustering
The cell type abundances of the Niche assay (which adds up to one for each Niche) can be normalized and processed like transcriptomics and proteomics profiles prior to clustering (i.e. niche clustering). We treat cell type abundances as compositional data, hence we incorporate centred log ratio (CLR) transformation for normalizing them.
vrMainFeatureType(MBrain_Sec) <- "Niche"
MBrain_Sec <- normalizeData(MBrain_Sec, method = "CLR")The CLR normalized assay have only 25 features, each representing a cell type from the single cell reference data. Hence, we can directly calculate UMAP reductions from this feature abundances since we don’t have much number of features which necessitates dimensionality reduction such as PCA.
However, we may still need to reduce the dimensionality of this space with 25 features using UMAP for visualizing purposes. VoltRon is also capable of calculating the UMAP reduction from normalized data slots. Hence, we build a UMAP reduction from CLR data directly. However, UMAP will always be calculated from a PCA reduction by default (if a PCA embedding is found in the object).
MBrain_Sec <- getUMAP(MBrain_Sec, data.type = "norm")
vrEmbeddingPlot(MBrain_Sec, embedding = "umap", group.by = "Sample")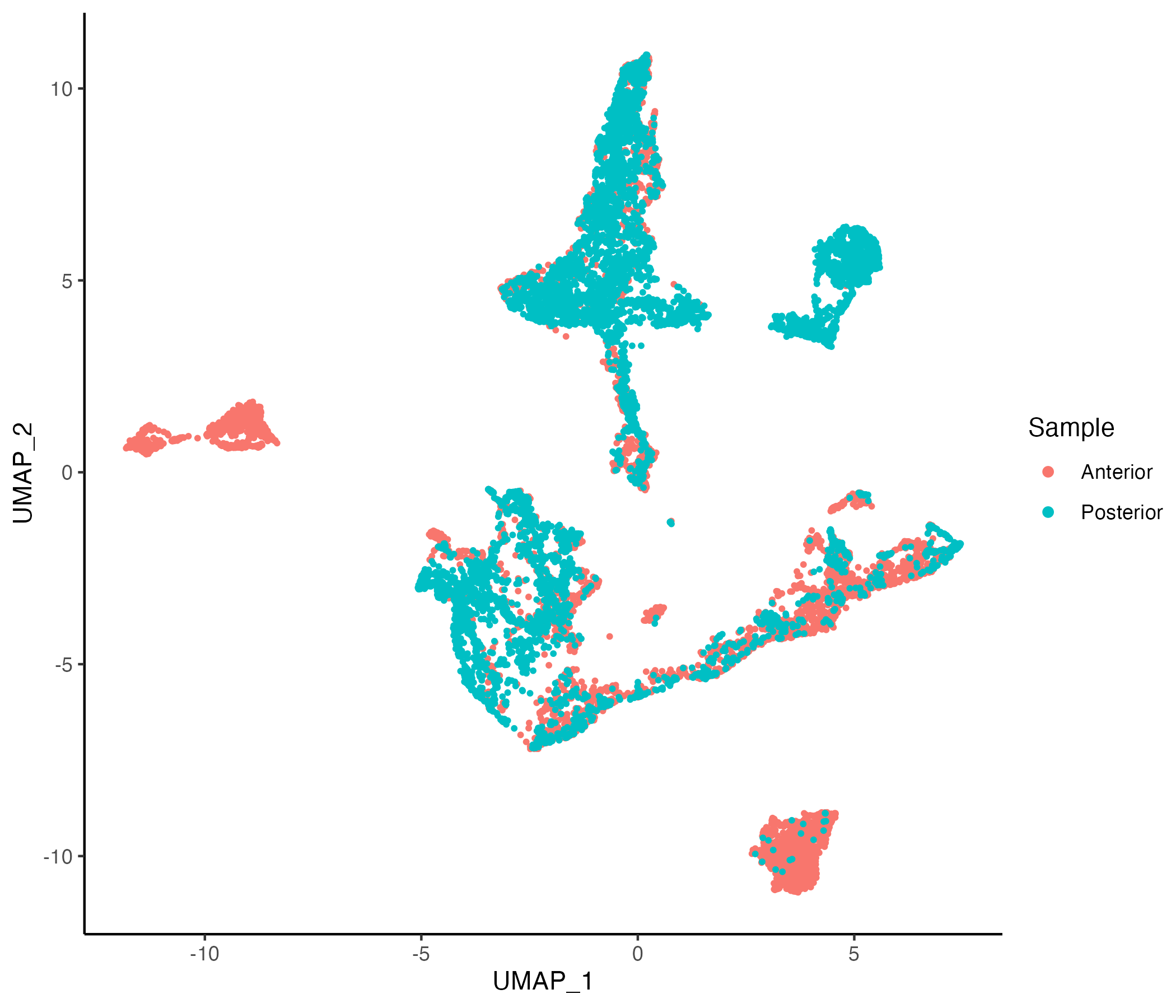
Using normalized cell type abundances, we can now cluster the niche profiles of spots using K-means clustering.
MBrain_Sec <- getClusters(MBrain_Sec, method = "kmeans", nclus = 8, label = "niche_clusters")Visualization
VoltRon incorporates distinct plotting functions for, e.g. embeddings, coordinates, heatmap and even barplots. We can now map the clusters we have generated on UMAP embeddings.
# visualize
g1 <- vrEmbeddingPlot(MBrain_Sec, embedding = "umap", group.by = "Sample")
g2 <- vrEmbeddingPlot(MBrain_Sec, embedding = "umap", group.by = "niche_clusters", label = TRUE)
g1 | g2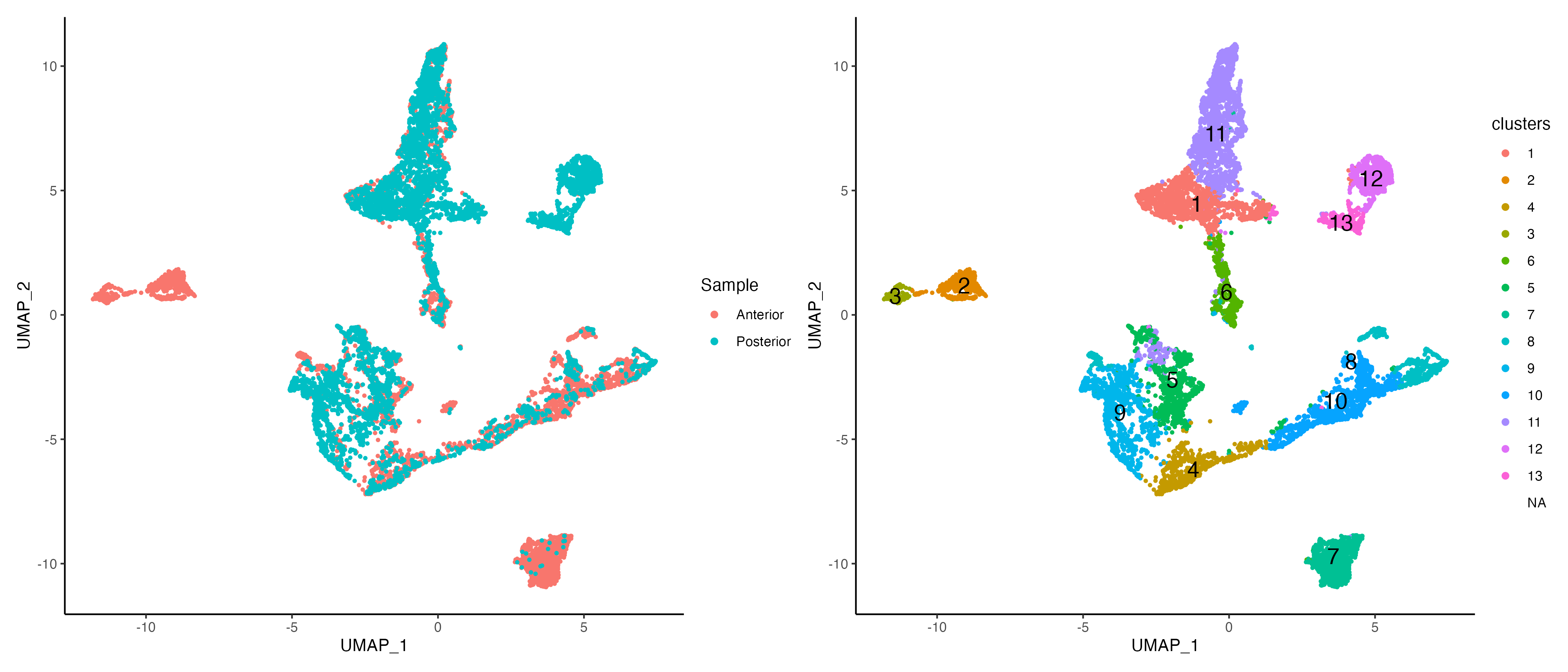
Mapping clusters on the spatial images and spots would show the niche structure across all four tissue sections.
vrSpatialPlot(MBrain_Sec, group.by = "niche_clusters", crop = TRUE, alpha = 1)
We use vrHeatmapPlot to investigate relative cell type abundances across these niche clusters. You will need to have ComplexHeatmap package in your namespace.
# install packages if necessary
if(!requireNamespace("ComplexHeatmap"))
BiocManager::install("ComplexHeatmap")
# heatmap of niches
library(ComplexHeatmap)
vrHeatmapPlot(MBrain_Sec, features = vrFeatures(MBrain_Sec), group.by = "niche_clusters",
show_row_names = T, show_heatmap_legend = T)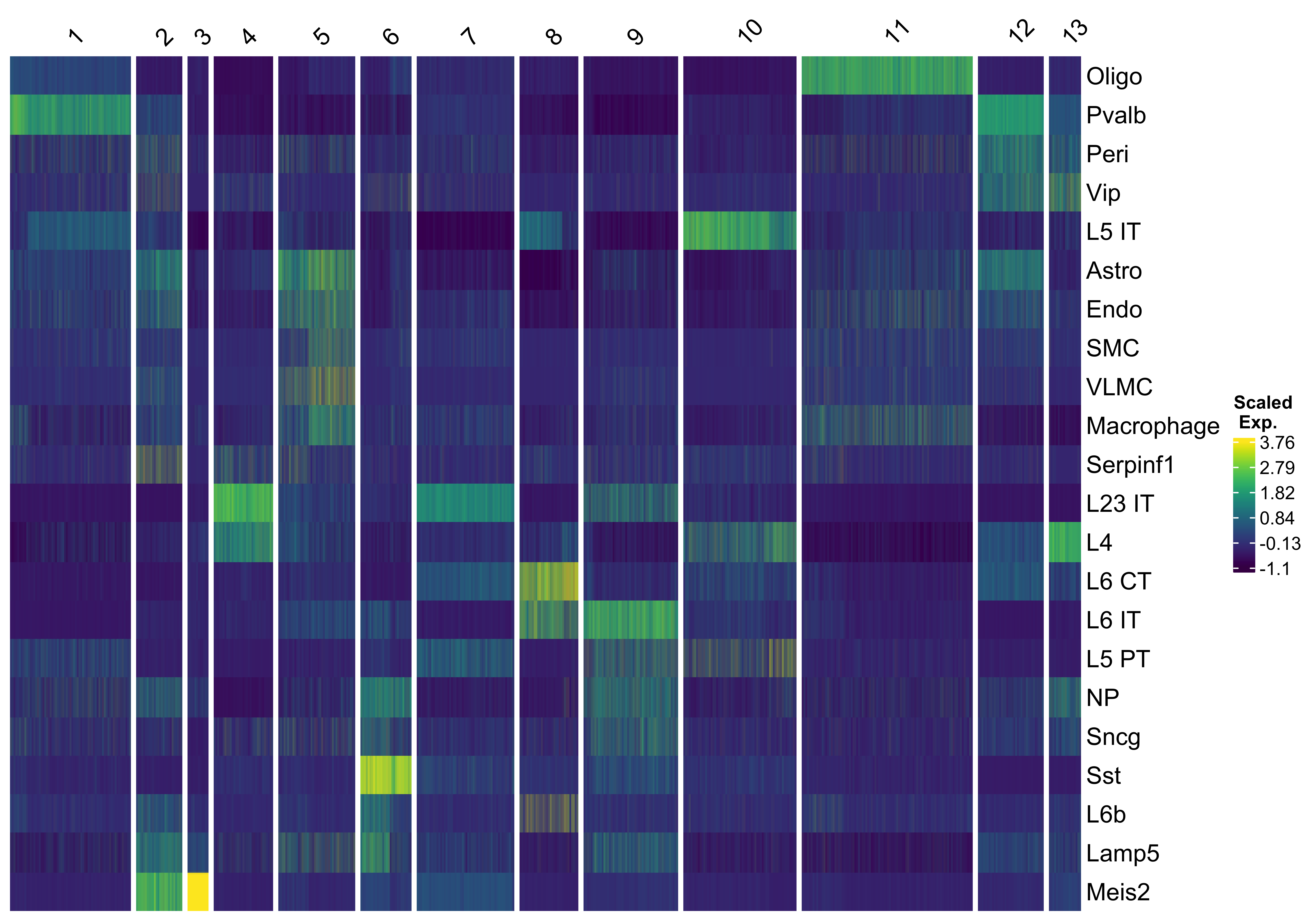
3D Niche Clustering (Spots)
A method to clustering Visium spots is using estimated cell type abundances per each spot as features for the 3D clustering task.
In this use case, we demonstrate 3D niche clustering on Visium data generated from tissue block sections of adult humans with postmortem dorsolateral prefrontal cortex (DLPFC). Two pairs of adjacent sections were obtained from the tissue block of the third donor. Each pair are composed of two 10 \(\mu\)m serial tissue sections, and pairs are located 300 \(\mu\)m apart from each other. Hence, we align each pair individually. The datasets can be downloaded from here.
We use the aligned DLPFC Visium datasets from here which includes four aligned Visium sections from human dorsolateral prefrontal cortex (DLPFC). See Spatial Data Alignment tutorial for more information on how to align multiple Visium sections into a VoltRon object.
Spot Deconvolution with RCTD
Thus, we first deconvolute spots into cells using a single cell reference in order to later use the resultsing cell type abundances per each spot for clustering. We will use the public single nucleus RNA-seq (snRNA-seq) data from available here. See (Tran, Maynard, Spangler et al., 2021) for more information.
We will use this reference for deconvoluting each Visium across each for Visium assay in the VoltRon object. See Niche Clustering tutorial for more information on spot deconvolution.
# single cell reference
load("SCE_DLPFC-n3_tran-etal.rda")
# prepare reference
tab <- table(sce.dlpfc.tran$cellType)
sce.dlpfc.tran <- sce.dlpfc.tran[,sce.dlpfc.tran$cellType %in% names(tab)[tab > 25]]
sce.dlpfc.tran.seu <- Seurat::as.Seurat(sce.dlpfc.tran)
# Spot deconvolution
library(spacexr)
SRBlock <- readRDS("Visium&Visium_data_registered.rds")
SRBlock <- getDeconvolution(SRBlock, sc.object = sce.dlpfc.tran,
sc.cluster = "cellType", max_cores = 2)
SRBlockVoltRon Object
DLPFC_Block:
Layers: Section1 Section2 Section3 Section4
Assays: Visium(Main)
Features: RNA(Main) Decon Creating Niche Assay
We can now calculate 3D neighbors across all spots in the tissue block, The registerSpatialData function by default returns VoltRon objects whose assays set to registered versions of spatial coordinates. Thus we can directly use getSpatialNeighbors function to calculate 3D neighbors.
# get 3D neighbors
SRBlock <- getSpatialNeighbors(SRBlock, method = "radius")The getNicheAssay function will aggregate the estimated cell type abundances of all neighboring spots into each spot to create a new feature data type.
# Calculate niche assay and clustering
vrMainFeatureType(SRBlock) <- "Decon"
SRBlock <- getNicheAssay(SRBlock, graph.type = "radius")
SRBlockVoltRon Object
DLPFC_Block:
Layers: Section1 Section2 Section3 Section4
Assays: Visium(Main)
Features: Decon(Main) RNA Niche Clustering
We will now use the new Niche feature set for 3D clustering where niche assay counts are first normalized using centred log ratio (CLR) transformation. We then use K-means for clustering spots into 7 clusters.
# Normalize before 3D clustering
vrMainFeatureType(SRBlock) <- "Niche"
SRBlock <- normalizeData(SRBlock, method = "CLR")
SRBlock <- getClusters(SRBlock, nclus = 7, method = "kmeans", label = "niche_clusters")
# visualize
vrSpatialPlot(SRBlock, group.by = "niche_clusters", alpha = 1, nrow = 2)
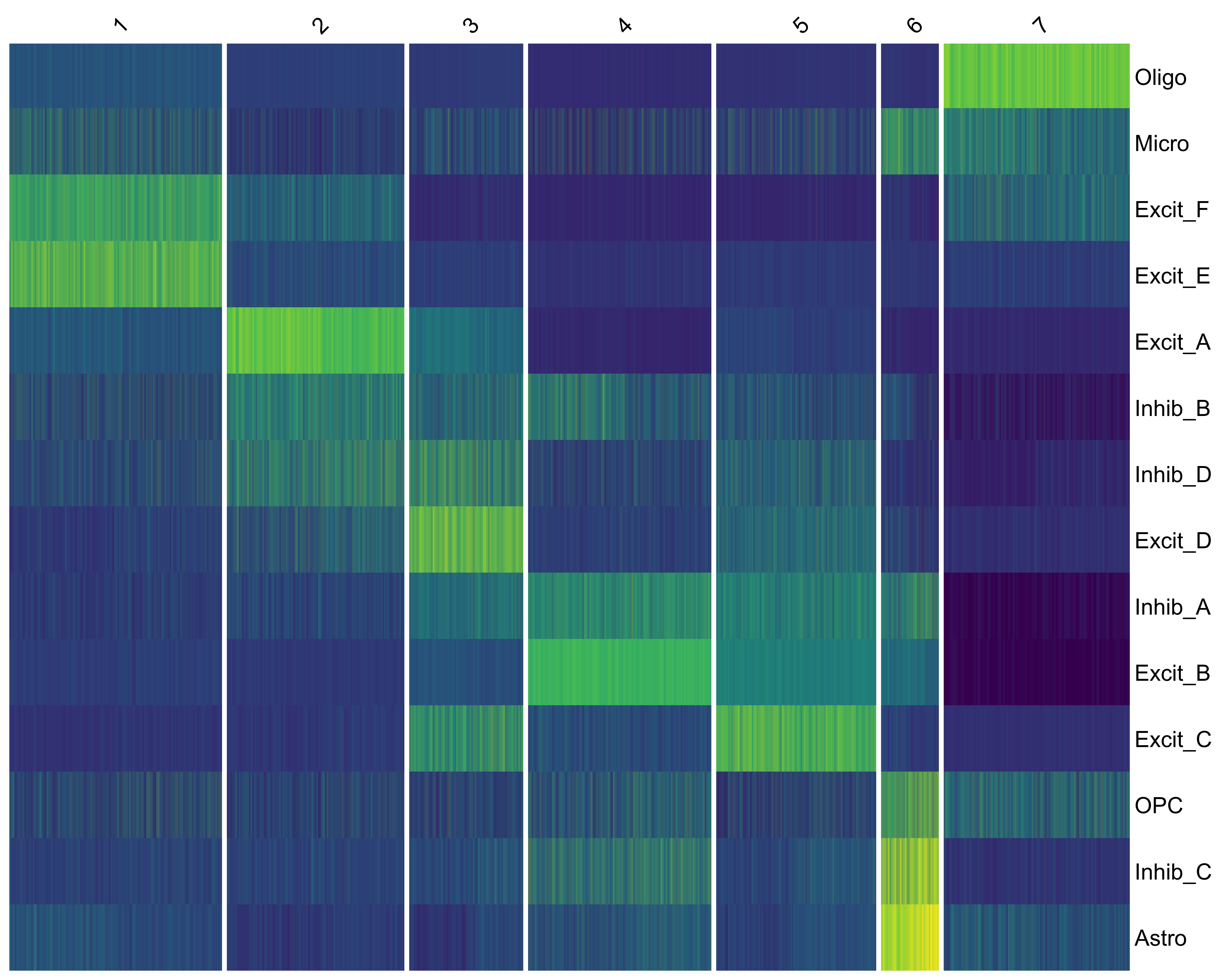
vrHeatmapPlot(SRBlock, features = vrFeatures(SRBlock), group.by = "niche_clusters")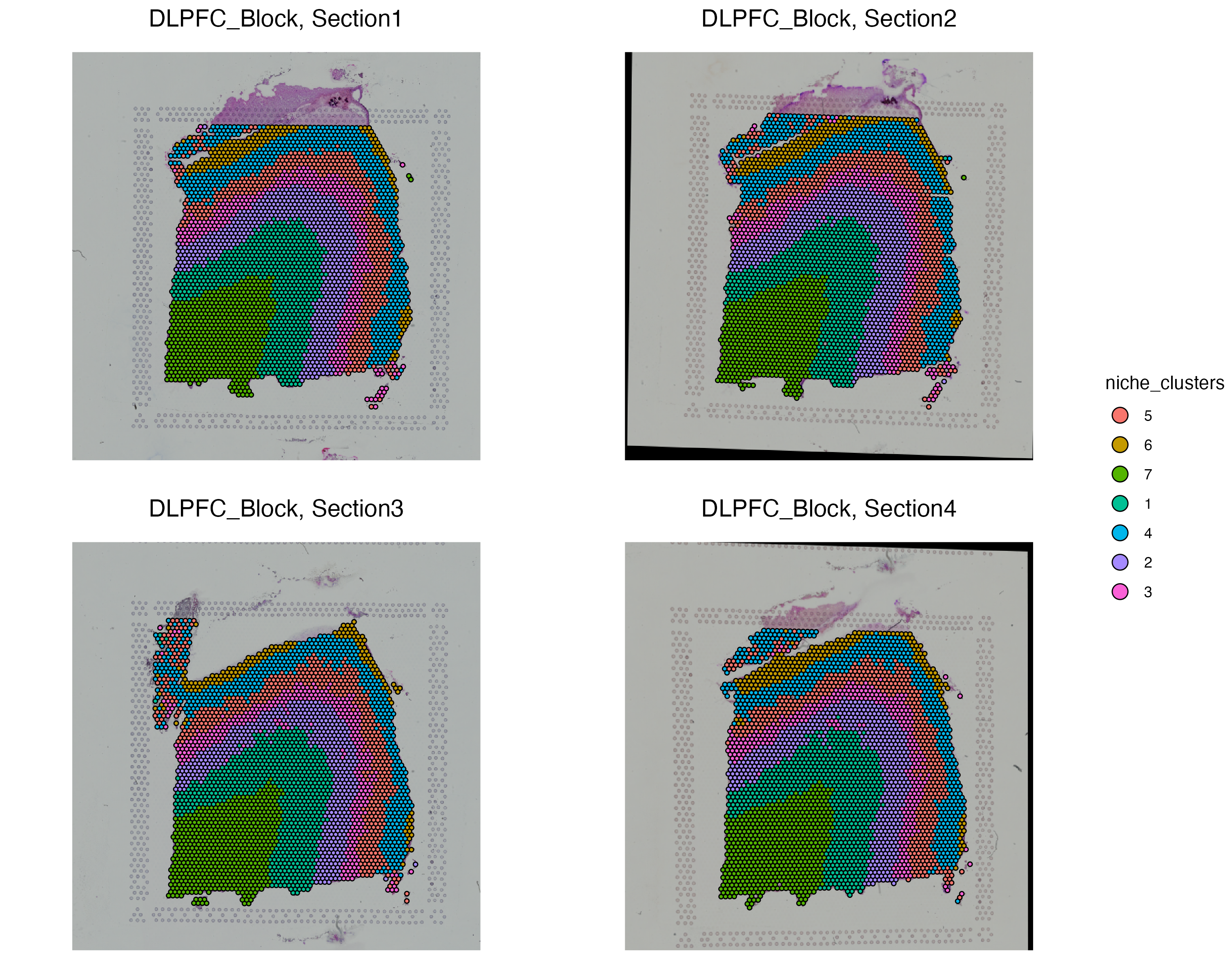
Cell-based Niche Clustering
Similar to spot-based spatial omics assays, we can build and cluster niche associated to each cell for spatial transcriptomics datasets in single cell resolution. For this, we require building niche assays for the collections of cells where a niche of cell is defined as a region of sets of regions with distinct cell type population that each of these cells belong to.
Here, we don’t require any scRNA reference dataset but we may first need to cluster and annotate cells in the RNA/transcriptome level profiles, and determine cell types. Then, we first detect the mixture of cell types within a spatial neighborhood around all cells and use that as a profile to perform clustering where these clusters will be associated with niches.
Import Xenium Data
For this, the data has to be already clustered (and annotated if possible). We will use the cluster labels generated at the end of the Xenium analysis workflow from Cell/Spot Analysis. You can download the VoltRon object with clustered and annotated Xenium cells along with the Visium assay from here.
Xen_data <- readRDS("VRBlock_data_clustered.rds")We will use all these 18 cell types used for annotating Xenium cells for detecting niches with distinct cellular type mixtures.
vrMainSpatial(Xen_data, assay = "Assay1") <- "main"
vrMainSpatial(Xen_data, assay = "Assay3") <- "main"
vrSpatialPlot(Xen_data, group.by = "CellType", pt.size = 0.13, background.color = "black",
legend.loc = "top", n.tile = 500)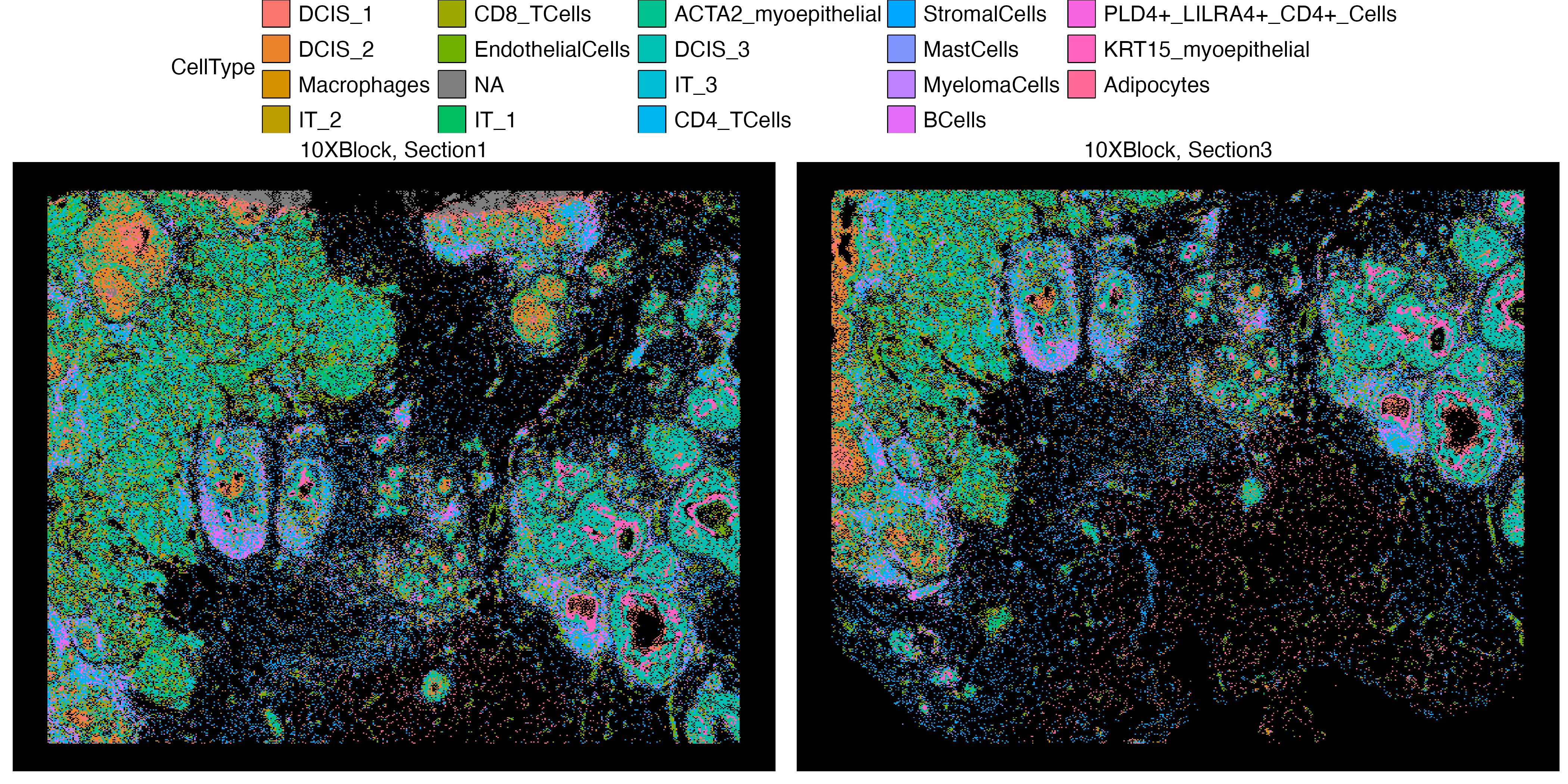
Creating Niche Assay
For calculating niche profiles for each cell, we have to first build spatial neighborhoods around cells and capture the local cell type mixtures. Using getSpatialNeighbors, we build a spatial neighborhood graph to connect all cells to other cells within at most 15 distance apart.
Xen_data <- getSpatialNeighbors(Xen_data, radius = 15, method = "radius")
vrGraphNames(Xen_data)[1] "radius"Now, we can build a niche assay for cells using the getNicheAssay function which will create an additional feature set for cells called Niche. Here, each cell type is a feature and the profile of a cell represents the relative abundance of cell types around each cell.
Xen_data <- getNicheAssay(Xen_data, label = "CellType", graph.type = "radius")
Xen_dataVoltRon Object
10XBlock:
Layers: Section1 Section2 Section3
Assays: Xenium(Main) Visium
Features: RNA(Main) NicheClustering
The Niche assay can be normalized similar to the spot-level niche analysis using centred log ratio (CLR) transformation.
vrMainFeatureType(Xen_data) <- "Niche"
Xen_data <- normalizeData(Xen_data, method = "CLR")Default clustering functions could be used to analyze the normalized niche profiles of cells to detect niches associated with each cell. However, we use K-means algorithm to perform the niche clustering. For this exercise, we pick an estimate of 7 clusters which will be the number of niche clusters we get.
Xen_data <- getClusters(Xen_data, nclus = 7, method = "kmeans", label = "niche_clusters")After the niche clustering, the metadata is updated and observed later like below.
head(Metadata(Xen_data)) id Count assay_id Assay Layer Sample CellType niche_clusters
1_Assay1 1_Assay1 28 Assay1 Xenium Section1 10XBlock DCIS_1 2
2_Assay1 2_Assay1 94 Assay1 Xenium Section1 10XBlock DCIS_2 2
3_Assay1 3_Assay1 9 Assay1 Xenium Section1 10XBlock DCIS_1 2
4_Assay1 4_Assay1 11 Assay1 Xenium Section1 10XBlock DCIS_1 2
5_Assay1 5_Assay1 48 Assay1 Xenium Section1 10XBlock DCIS_2 2
6_Assay1 6_Assay1 7 Assay1 Xenium Section1 10XBlock DCIS_1 2Visualization
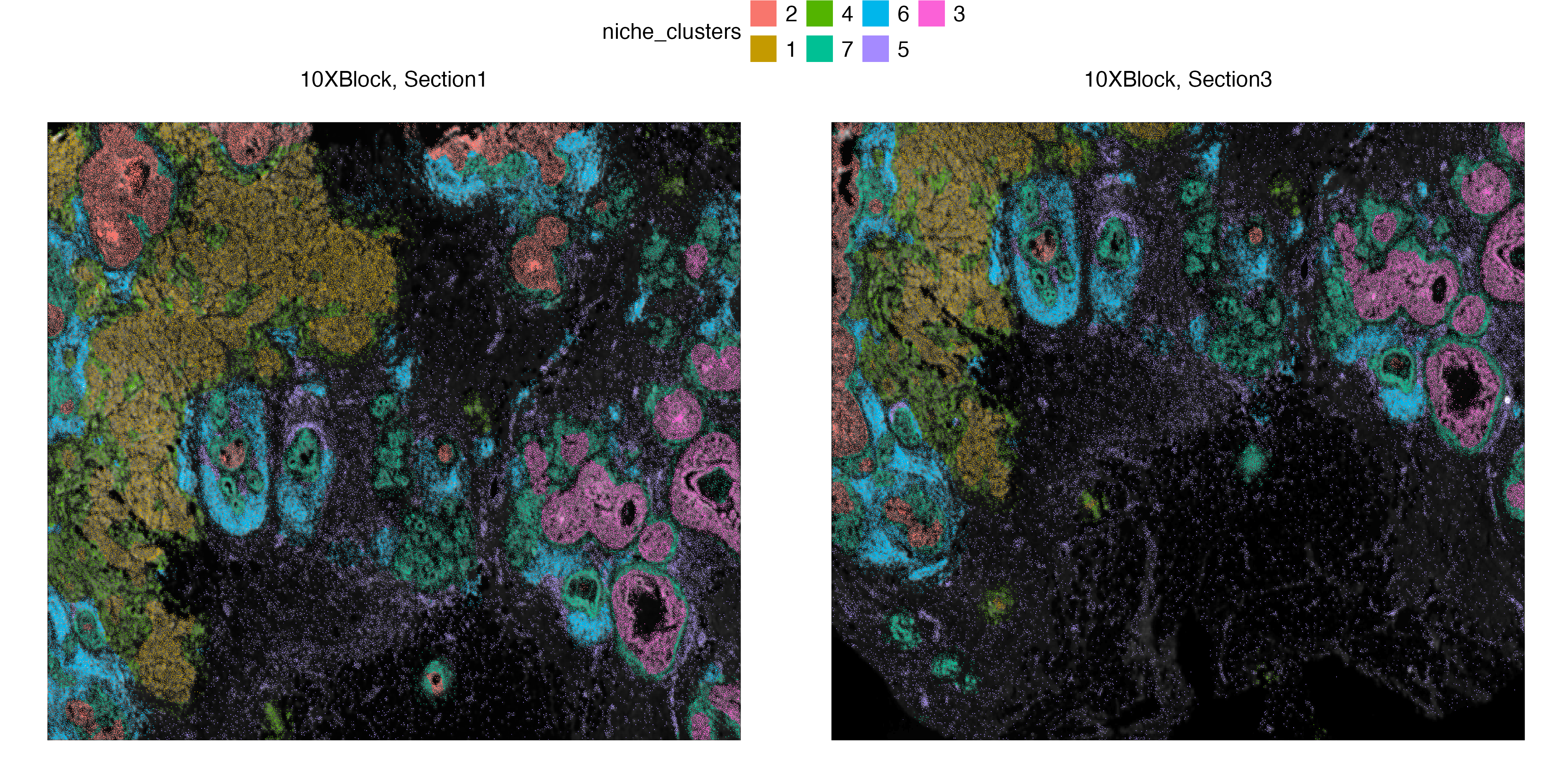
After niche clustering, each cell in the Xenium assay will be assigned a niche which is initially a number which indicates the ID of each particular niche. It is up to the user to annotate, filter and visualize these niches moving forward.
vrSpatialPlot(Xen_data, group.by = "niche_clusters", alpha = 1, legend.loc = "top")We use vrHeatmapPlot to investigate the abundance of each cell type across the niche clusters. You will need to have ComplexHeatmap package in your namespace. We see that niche cluster 1 include all invasive tumor subtypes (IT 1-3). We see this for two subtypes of in situ ductal carcinoma (DCIS 1,2) subtypes as well other than a third DCIS subcluster being within proximity to myoepithelial cells. Niche cluster 6 also shows regions within the breast cancer tissue where T cells and B cells are found together abundantly.
# install packages if necessary
if(!requireNamespace("ComplexHeatmap"))
BiocManager::install("ComplexHeatmap")
# heatmap of niches
library(ComplexHeatmap)
vrHeatmapPlot(Xen_data, features = vrFeatures(Xen_data), group.by = "niche_clusters")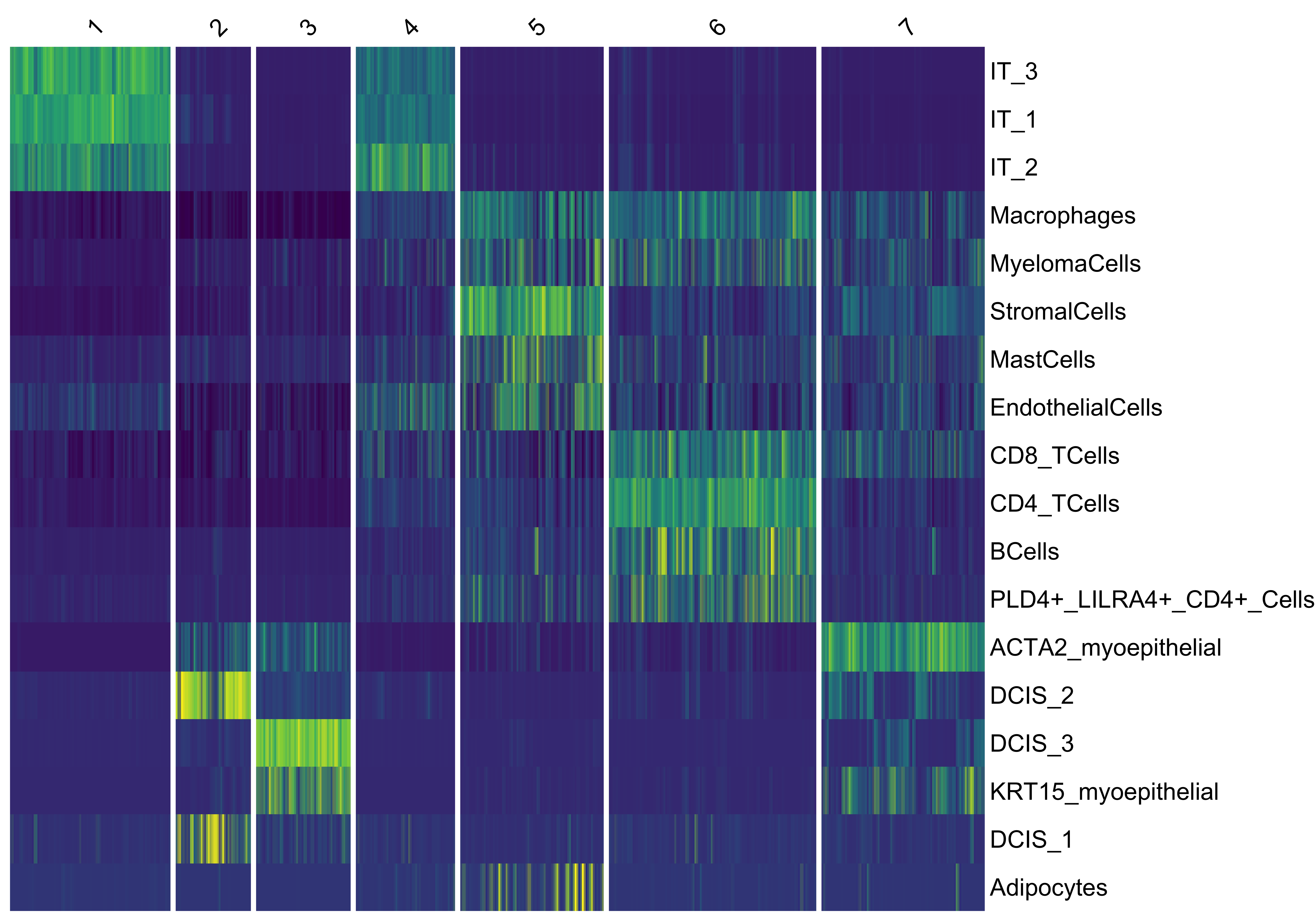
3D Niche Clustering (Cells)
VoltRon extends coordinate spaces to three dimensions, thus allow analyzing the proximity across observations in three dimensions.
Import OpenST Data
We will use the OpenST https://rajewsky-lab.github.io/openst/latest/ assays to capture cells in 3D and detect tissue niches of the metastatic lymph node example that is deposited to NCBI/GEO (GSE251926). Please use the GSE251926_metastatic_lymph_node_3d.h5ad.gz file and unzip it to use the importOpenST function below.
vr_openst <- importOpenST(h5ad.path = "GSE251926_metastatic_lymph_node_3d.h5ad",
sample_name = "MLN_3D", assay_name = "OpenST")
vr_openstVoltRon Object
MLN_3D:
Layers: Section1 Section2 Section3 Section4 Section5
Section6 Section7 Section8 Section9 Section10
Section11 Section12 Section13 Section14 Section15
Section16 Section17 Section18 Section19
Assays: OpenST(Main)
Features: RNA(Main) OpenST cells from GSE251926 are already called and annotated. See the OpenST paper for more information.
vrSpatialPlot(vr_openst, assay = c("Assay1", "Assay2", "Assay3", "Assay4"),
group.by = "annotation", n.tile = 400, alpha = 1, ncol = 2,
background.color = "black")
The importOpenST function automatically detects sections of an OpenST readout and create a block of these sections in the form of a VoltRon object. Here, we have more than 1 million cells across 19 tissue sections.
length(vrSpatialPoints(vr_openst))[1] 1097769VoltRon Objects on Disk
VoltRon provide utilities to store (i) large images and (ii) large feature vs observation matrices on disk for decreased memory consumption. We use the saveVoltRon function to determine a location for large data matrices to be stored. We choose HDF5VoltRon as the format, indicating the feature profiles of these 1 million cells to be stored in a separate .h5 file in the output.
vr_openst <- saveVoltRon(vr_openst,
format = "HDF5VoltRon",
output = "data/OnDisk/OpenST/mln3d/",
replace = TRUE)A saved VoltRon object on disk can be loaded given the location.
vr_openst <- loadVoltRon(dir = "data/OnDisk/OpenST/mln3d/")Creating Niche Assay for 3D
Once the on-disk VoltRon object is loaded, the niche clustering workflow is followed similar to the Xenium example above. We can check the three dimensional coordinates (with z axis) of all one million cells using again the vrCoordinates function.
head(vrCoordinates(vr_openst)) x y z
2_307_Assay1 259 4848 57.97101
2_309_Assay1 259 5448 57.97101
2_446_Assay1 313 5640 57.97101
2_655_Assay1 493 6225 57.97101
2_656_Assay1 495 6262 57.97101
2_658_Assay1 495 6319 57.97101Let us capture the relative cell type mixture around each cell using a spatial proximity graph. We will use this graph to build a niche assay whose features are cell type and measures are proportional abundance of each cell type around that cell.
vr_openst <- getSpatialNeighbors(vr_openst, radius = 60, method = "radius")
vr_openst <- getNicheAssay(vr_openst, label = "annotation",
graph.type = "radius", new_feature_name = "Niche_60")We visualize the SPP1 expression of cells, which is a marker for M1 macrophages, in the first two adjacent sections, and also visualize the relative amount of M1 macrophages neighboring each cell.
vrMainFeatureType(vr_openst) <- "RNA"
vrSpatialFeaturePlot(vr_openst, assay = c("Assay1", "Assay2"),
features = "SPP1", n.tile = 400, alpha = 1,
background.color = "black")
vrMainFeatureType(vr_openst) <- "Niche_60"
vrSpatialFeaturePlot(vr_openst, assay = c("Assay1", "Assay2"),
features = "M1_macrophages", n.tile = 400, alpha = 1,
background.color = "black")
Clustering
We incorporate centred log ratio (CLR) transformation for normalizing cell type abundances before K-means clustering.
vr_openst <- normalizeData(vr_openst, method = "CLR")
vr_openst <- getClusters(vr_openst, nclus = 6,
method = "kmeans", label = "niche_clusters")Visualization
if(!requireNamespace("patchwork"))
install.packages("patchwork")
library(patchwork)
g1 <- vrSpatialPlot(vr_openst, assay = "Assay1", group.by = "niche_clusters",
background.color = "black", n.tile = 400, alpha = 1)
g2 <- vrSpatialPlot(vr_openst, assay = "Assay1", group.by = "annotation",
background.color = "black", n.tile = 400, alpha = 1)
g3 <- vrSpatialPlot(vr_openst, assay = "Assay2", group.by = "niche_clusters",
background.color = "black", n.tile = 400, alpha = 1)
g4 <- vrSpatialPlot(vr_openst, assay = "Assay2", group.by = "annotation",
background.color = "black", n.tile = 400, alpha = 1)
(g1 | g2) / (g3 | g4)
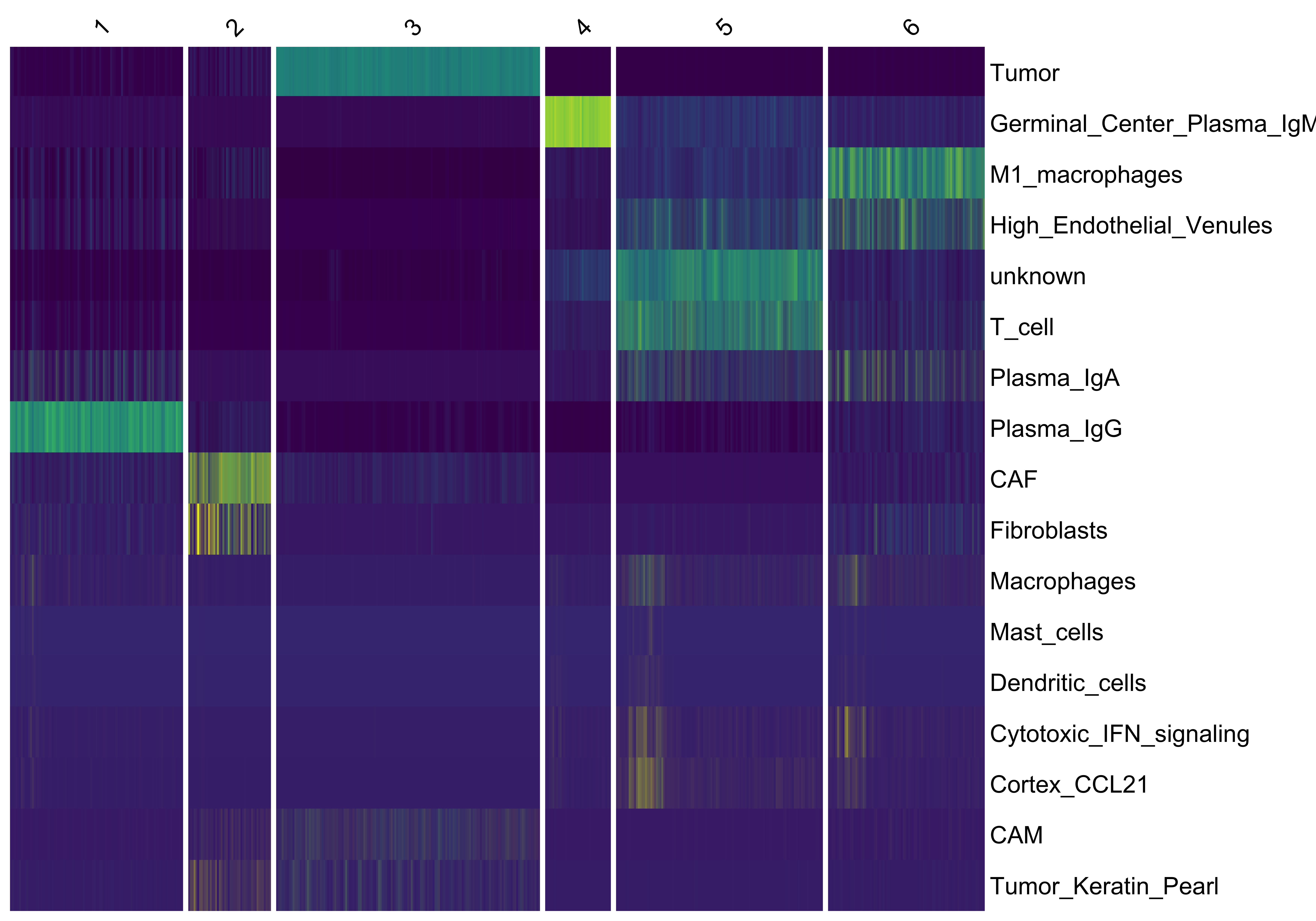
We use vrHeatmapPlot to investigate the abundance of each cell type across the niche clusters. You will need to have ComplexHeatmap package in your namespace. We see a clear separation of e.g. Tumor, Plasma cells (IGHG3+), and macrophages, where M1 macrophages mostly compose separate niches compared to T cells although both groups are found in niches along with IGHA1+ Plasma cells and Endothelial Venules.
# install packages if necessary
if(!requireNamespace("ComplexHeatmap"))
BiocManager::install("ComplexHeatmap")
# heatmap of niches
library(ComplexHeatmap)
vrHeatmapPlot(vr_openst, features = vrFeatures(vr_openst),
group.by = "niche_clusters")